Troubleshooting Azure Cosmos DB Performance
In this lab, you will use the Java SDK to tune Azure Cosmos DB requests to optimize the performance and cost of your application.
If this is your first lab and you have not already completed the setup for the lab content see the instructions for Account Setup before starting this lab.
Open the CosmosLabs Maven Project Template
-
Open Visual Studio Code.
-
If you are completing this lab through Microsoft Hands-on Labs, the CosmosLabs folder will be located at the path: your\home\directory\Documents\CosmosLabs. In Visual Studio Code, go to File > Open Folder > to get an Open Folder dialog and and use the dialog to open the CosmosLabs folder.
-
Expand the directory tree to src\main\java\com\azure\cosmos\handsonlabs\lab09\ folder. This directory is where you will develop code for this Lab. You should see only a Lab09Main.java file - this is the
mainclass for the project. -
Open Lab09Main.java in the editor by clicking on it in the Explorer pane.
-
In the Visual Studio Code window, in the Explorer pane, right-click the empty space in pane and choose the Open in Terminal menu option.
-
Let’s start by building the template code. In the open terminal pane, enter and execute the following command:
mvn clean packageThis command will build the console project.
-
Click the 🗙 symbol to close the terminal pane.
-
For the
endpointUrivariable, replace the placeholder value with the URI value and for theprimaryKeyvariable, replace the placeholder value with the PRIMARY KEY value from your Azure Cosmos DB account. Use these instructions to get these values if you do not already have them:For example, if your uri is
https://cosmosacct.documents.azure.com:443/, your new variable assignment will look like this:private static String endpointUri = "https://cosmosacct.documents.azure.com:443/";.For example, if your primary key is
elzirrKCnXlacvh1CRAnQdYVbVLspmYHQyYrhx0PltHi8wn5lHVHFnd1Xm3ad5cn4TUcH4U0MSeHsVykkFPHpQ==, your new variable assignment will look like this:private static String primaryKey = "elzirrKCnXlacvh1CRAnQdYVbVLspmYHQyYrhx0PltHi8wn5lHVHFnd1Xm3ad5cn4TUcH4U0MSeHsVykkFPHpQ==";.We are now going to implement a sample query to make sure our client connection code works.
Examining Response Headers
Azure Cosmos DB returns various response headers that can give you more metadata about your request and what operations occurred on the server-side. The Java SDK exposes many of these headers to you as properties of the ResourceResponse<> class.
Observe RU Charge for Large Item
-
Locate the client-create/client-close block within the
mainmethod:CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); -
After the last line of code in the using block, add a new line of code to create a new object and store it in a variable named
person:Person person = new Person();The
Personclass uses the Faker library to generate a fictional person with randomized properties. Here’s an example of a fictional person JSON document:{ "website":"boehm.com", "gender":"female", "firstName":"Aurea", "lastName":"Schmeler", "userName":"rhoda.price", "avatar":"Rocky Mountain", "email":"porter.abbott@gmail.com", "dateOfBirth":-85629219547, "address":{ "street":"Daron", "suite":"9578", "city":"Schoenhaven", "state":"Massachusetts", "zipCode":"97232", "geo":{ "lat":-3.74887, "lng":128.71832 } }, "phone":"755-113-3899 x227", "company":{ "name":"Thompson LLC", "catchPhrase":"Visionary dynamic strategy", "bs":"embrace proactive infrastructures" } } -
Add a new line of code to invoke the
createItemmethod of theCosmosAsyncContainerinstance using thepersonvariable as a parameter:CosmosItemResponse<Person> response = peopleContainer.createItem(person).block(); -
After the last line of code in the using block, add a new line of code to print out the value of the RequestCharge property of the ItemResponse<> instance:
logger.info("{} RUs", response.getRequestCharge()); -
Your
mainmethod should now look like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); Person person = new Person(); CosmosItemResponse<Person> response = peopleContainer.createItem(person).block(); logger.info("First item insert: {} RUs", response.getRequestCharge()); client.close(); } -
Save all of your open editor tabs.
-
In the Explorer pane, right-click Lab09Main.java and choose the Run menu option.
This command will build and execute the console project.
-
Observe the results of the console project.
You should see the document creation operation use between 10 and 20 RUs.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node and then select the PeopleCollection node.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT TOP 2 * FROM coll ORDER BY coll._ts DESCThis query will return the latest two items added to your container.
-
Click the Execute Query button in the query tab to run the query.
-
In the Results pane, observe the results of your query.
-
Return to the currently open Visual Studio Code editor containing your Java project.
-
In the Visual Studio Code window, double-click the Lab09Main.java file to open an editor tab for the file.
-
To view the RU charge for inserting a very large document, we will create a
Familyinstance. TheFamilyclass uses the Faker library to create a fictional family on ourMemberobject. To create a fictional family, we will generate a spouse and an array of 4 fictional children:{ "accountHolder": { ... }, "relatives": { "spouse": { ... }, "children": [ { ... }, { ... }, { ... }, { ... } ] } }Each property will have a Faker-generated fictional person. This should create a large JSON document that we can use to observe RU charges.
-
Within the Lab09Main.java editor tab, locate the
mainmethod. -
Within the
mainmethod, locate the following line of code:Person person = new Person(); CosmosItemResponse<Person> response = peopleContainer.createItem(person).block(); logger.info("First item insert: {} RUs", response.getRequestCharge());Replace that line of code with the following code:
List<Person> children = new ArrayList<Person>(); for (int i=0; i<4; i++) children.add(new Person()); Member member = new Member(UUID.randomUUID().toString(), new Person(), // accountHolder new Family(new Person(), // spouse children)); // children CosmosItemResponse<Member> response = peopleContainer.createItem(member).block(); logger.info("Second item insert: {} RUs", response.getRequestCharge());This new block of code will create the large JSON object discussed above.
-
Save all of your open editor tabs.
-
Right-click and run the project as you did previously.
-
Observe the results of the console project.
You should see this new operation require far more RUs than the simple JSON document.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node and then select the PeopleCollection node.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.relatives)This query will return the only item in your container with a property named Children.
-
Click the Execute Query button in the query tab to run the query.
-
In the Results pane, observe the results of your query.
Tune Index Policy
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the PeopleCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Indexing Policy field and observe the current default indexing policy:
{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*", "indexes": [ { "kind": "Range", "dataType": "Number", "precision": -1 }, { "kind": "Range", "dataType": "String", "precision": -1 }, { "kind": "Spatial", "dataType": "Point" } ] } ], "excludedPaths": [ { "path":"/\"_etag\"/?" } ] }This policy will index all paths in your JSON document. This policy implements maximum precision (-1) for both numbers (max 8) and strings (max 100) paths. This policy will also index spatial data.
-
Replace the indexing policy with a new policy that removes the
/relatives/*path from the index:{ "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path":"/*", "indexes":[ { "kind": "Range", "dataType": "String", "precision": -1 }, { "kind": "Range", "dataType": "Number", "precision": -1 } ] } ], "excludedPaths": [ { "path":"/\"_etag\"/?" }, { "path":"/relatives/*" } ] }This new policy will exclude the
/relatives/*path from indexing effectively removing the Children property of your large JSON document from the index. -
Click the Save button at the top of the section to persist your new indexing policy and “kick off” a transformation of the container’s index.
-
Click the New SQL Query button at the top of the Data Explorer section.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.relatives) -
Click the Execute Query button in the query tab to run the query.
You will see immediately that you can still determine if the /relatives path is defined.
-
In the query tab, replace the contents of the query editor with the following SQL query:
SELECT * FROM coll WHERE IS_DEFINED(coll.relatives) ORDER BY coll.relatives.Spouse.FirstName -
Click the Execute Query button in the query tab to run the query.
This query will fail immediately since this property is not indexed. Keep in mind when defining indexes that only indexed properties can be used in query conditions.
-
Now, return to Visual Studio code and run the project.
-
Observe the results of the console project.
You should see a difference in the number of RUs required to create this item. This is due to the indexer skipping the paths you excluded.
-
Click the 🗙 symbol to close the terminal pane.
Troubleshooting Requests
First, you will use the Java SDK to issue a request beyond the assigned capacity for a container. Request unit consumption is evaluated at a per-second rate. For applications that exceed the provisioned request unit rate, requests are rate-limited until the rate drops below the provisioned throughput level. When a request is rate-limited, the server preemptively ends the request with an HTTP status code of 429 RequestRateTooLargeException and returns the x-ms-retry-after-ms header. The header indicates the amount of time, in milliseconds, that the client must wait before retrying the request. You will observe the rate-limiting of your requests in an example application.
Reducing RU Throughput for a Container
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the TransactionCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Throughput field and update it’s value to 400.
This is the minimum throughput that you can allocate to a container.
-
Click the Save button at the top of the section to persist your new throughput allocation.
Observing Throttling (HTTP 429)
-
Return to the currently open Visual Studio Code editor containing your Java project.
-
Double-click the Lab09Main.java link in the Explorer pane to open the file in the editor.
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); }For the next few instructions, we will generate test data by creating 100
Transactioninstances. Internally the emptyTransactionconstructor uses the Faker library to populate the object fields. For this lab, our intent is to focus on Azure Cosmos DB instead of this library; therefore we will introduce the code that creates the dataset but not spend too much time discussing how it works internally. -
Add the following code to create a collection of
Transactioninstances:List<Transaction> transactions = new ArrayList<Transaction>(); for (int i=0; i<100; i++) transactions.add(new Transaction()); -
Add the following foreach block to iterate over the
Transactioninstances:for (Transaction transaction : transactions) { } -
Within the foreach block, add the following line of code to asynchronously create an item and save the result of the creation task to a variable:
CosmosItemResponse<Transaction> result = transactionContainer.createItem(transaction).block();The
createItemmethod of theCosmosAsyncContainerclass takes in an object that you would like to serialize into JSON and store as an item within the specified collection. -
Still within the foreach block, add the following line of code to write the value of the newly created resource’s
idproperty to the console:logger.info("Item Created {}", result.getItem().getId());The
CosmosItemResponsetype has an access method namedgetItemthat can give you access to the item instance resulting from the operation. -
Your
mainmethod should look like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); List<Transaction> transactions = new ArrayList<Transaction>(); for (int i=0; i<100; i++) transactions.add(new Transaction()); for (Transaction transaction : transactions) { CosmosItemResponse<Transaction> result = transactionContainer.createItem(transaction).block(); logger.info("Item Created {}", result.getItem().getId()); } client.close(); }As a reminder, under the hood the Faker library generates a set of test data inside of the
Transactionconstructor. -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see a list of item ids associated with new items that are being created by this tool.
-
Click the 🗙 symbol to close the terminal pane.
-
Although this code uses the Async API to insert documents into an Azure Cosmos DB container, we are using the API in a synchronous manner by blocking on each
createItemcall. A sync implementation on one thread probably can’t saturate the container provisioned throughput. Now let’s rewrite thesecreateItemcalls in an async Reactive Programming fashion and see what happens when we saturate the full 400 RU/s provisioned for the container. Back in the code editor tab, locate the following lines of code:for (Transaction transaction : transactions) { CosmosItemResponse<Transaction> result = transactionContainer.createItem(transaction).block(); logger.info("Item Created {}", result.getItem().getId()); }Replace those lines of code with the following code:
Flux<Transaction> interactionsFlux = Flux.fromIterable(transactions); List<CosmosItemResponse<Transaction>> results = interactionsFlux.flatMap(interaction -> { return transactionContainer.createItem(interaction); }) .collectList() .block(); results.forEach(result -> logger.info("Item Created\t{}",result.getItem().getId()));We are going to attempt to run as many of these creation tasks in parallel as possible. Remember, our container is configured at 400 RU/s.
-
Your
mainmethod should look like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); List<Transaction> transactions = new ArrayList<Transaction>(); for (int i=0; i<100; i++) transactions.add(new Transaction()); Flux<Transaction> interactionsFlux = Flux.fromIterable(transactions); List<CosmosItemResponse<Transaction>> results = interactionsFlux.flatMap(interaction -> { return transactionContainer.createItem(interaction); }) .collectList() .block(); results.forEach(result -> logger.info("Item Created\t{}",result.getItem().getId())); client.close(); }In this implementation we use a Reactor factory method
Flux.fromIterableto create a Reactive FluxinteractionsFluxfrom ourTransactionlist. We then useinteractionsFluxas thePublisherin a Reactive Streams pipeline which issues successivecreateItemrequests without waiting for the previous request to complete. Thus this is an Async implementation. The for-each loop at the end of this code block iterates over the request results and prints a notification for each. Since these requests are issued nearly in parallel, increasing the number of documents should quickly cause an exceptional scenario since your Azure Cosmos DB container does not have enough assigned throughput to handle the volume of requests. -
Save all of your open editor tabs.
-
In the Visual Studio Code window, right-click the Explorer pane and select the Open in Terminal menu option.
-
Run the project.
-
Observe the output of the console application.
This query should execute successfully. We are only creating 100 items and we most likely will not run into any throughput issues here.
-
Click the 🗙 symbol to close the terminal pane.
-
Back in the code editor tab, locate the following line of code:
for (int i=0; i<100; i++) transactions.add(new Transaction());Replace that line of code with the following code:
for (int i=0; i<5000; i++) transactions.add(new Transaction());We are going to try and create 5000 items in parallel to see if we can hit the container throughput limit. The numbers will depend highly on your PC hardware specs so you may need to tweak the document count.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe that the application will begin issuing error messages and possibly crash during this time.
This query will most likely hit our throughput limit. You will see multiple error messages indicating that specific requests have failed.
-
Click the 🗙 symbol to close the terminal pane.
Increasing RU Throughput to Reduce Throttling
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the TransactionCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Throughput field and update it’s value to 10000.
-
Click the Save button at the top of the section to persist your new throughput allocation.
-
Back in the code editor tab, locate the following line of code:
for (int i=0; i<5000; i++) transactions.add(new Transaction());Replace that line of code with the following code:
for (int i=0; i<10000; i++) transactions.add(new Transaction());We are going to try creating 10000 items in parallel against the new higher throughput limit.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe that the application will complete after some time.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Settings section in the Azure Portal and change the Throughput value back to 400.
-
Click the Save button at the top of the section to persist your new throughput allocation.
Tuning Queries and Reads
You will now tune your requests to Azure Cosmos DB by manipulating the SQL query and properties of the RequestOptions class in the Java SDK.
Measuring RU Charge
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); } -
Add the following line of code that will store a SQL query in a string variable:
String sql = "SELECT TOP 1000 * FROM c WHERE c.processed = true ORDER BY c.amount DESC";This query will perform a cross-partition ORDER BY and only return the top 1000 out of 50000 items.
-
Add the following Reactive Stream code which creates an item query instance. Let’s take only the first “page” of results. We’ll include a line which prints out the Request Charge metric for the query to the console:
We will not enumerate the full result set. We are only interested in the metrics for the first page of results.
CosmosQueryRequestOptions options = new CosmosQueryRequestOptions(); transactionContainer.queryItems(sql, options, Transaction.class) .byPage() .next() // Take only the first page .flatMap(page -> { logger.info("Request Charge: {} RUs",page.getRequestCharge()); return Mono.empty(); }).block(); -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see the Request Charge metric printed out in your console window.
-
Click the 🗙 symbol to close the terminal pane.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT TOP 1000 * FROM c WHERE c.processed = true ORDER BY c.amount DESC";Replace that line of code with the following code:
String sql = "SELECT * FROM c WHERE c.processed = true";This new query does not perform a cross-partition ORDER BY.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see a reduction in the Request Charge value.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT * FROM c WHERE c.processed = true";Replace that line of code with the following code:
String sql = "SELECT * FROM c";This new query does not filter the result set.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
The Request Charge should be even lower.
-
Back in the code editor tab, locate the following line of code:
String sql = "SELECT * FROM c";Replace that line of code with the following code:
String sql = "SELECT c.id FROM c";This new query does not filter the result set.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
Observe the slight differences in the Request Charge value.
Managing SDK Query Options
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); } -
Add the following lines of code to create variables to configure query options:
int maxItemCount = 100; int maxDegreeOfParallelism = 1; int maxBufferedItemCount = 0; -
Add the following lines of code to configure options for a query from the variables:
CosmosQueryRequestOptions options = new CosmosQueryRequestOptions(); options.setMaxBufferedItemCount(maxBufferedItemCount); options.setMaxDegreeOfParallelism(maxDegreeOfParallelism); -
Add the following code to write various values to the console window:
logger.info("\n\n" + "MaxItemCount:\t{}\n" + "MaxDegreeOfParallelism:\t{}\n" + "MaxBufferedItemCount:\t{}" + "\n\n", maxItemCount, maxDegreeOfParallelism, maxBufferedItemCount); -
Add the following line of code that will store a SQL query in a string variable:
String sql = "SELECT * FROM c WHERE c.processed = true ORDER BY c.amount DESC";This query will perform a cross-partition ORDER BY on a filtered result set.
-
Add the following line of code to create and start new a high-precision timer:
StopWatch timer = StopWatch.createStarted(); -
Add the following line of code to create a item query instance and enumerate the result set:
transactionContainer.queryItems(sql, options, Transaction.class) .byPage(maxItemCount) .flatMap(page -> { //Don't do anything with the query page results return Mono.empty(); }).blockLast();Since the results are paged and the pages are exposed a
Flux, we will useflatMapto service each page. -
Add the following line of code stop the timer:
timer.stop(); -
Add the following line of code to write the timer’s results to the console window:
logger.info("\n\nElapsed Time:\t{}s\n\n", ((double)timer.getTime(TimeUnit.MILLISECONDS))/1000.0); -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
This initial query should take an unexpectedly long amount of time. This will require us to optimize our SDK options.
-
Back in the code editor tab, locate the following line of code:
int maxDegreeOfParallelism = 1;Replace that line of code with the following:
int maxDegreeOfParallelism = 5;Setting the
maxDegreeOfParallelismquery parameter to a value of1effectively eliminates parallelism. Here we “bump up” the parallelism to a value of5. -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see a slight difference considering you now have some form of parallelism.
-
Back in the code editor tab, locate the following line of code:
int maxBufferedItemCount = 0;Replace that line of code with the following code:
int maxBufferedItemCount = -1;Setting the
MaxBufferedItemCountproperty to a value of-1effectively tells the SDK to manage this setting. -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
Again, this should have a slight impact on your performance time.
-
Back in the code editor tab, locate the following line of code:
int maxDegreeOfParallelism = 5;Replace that line of code with the following code:
int maxDegreeOfParallelism = -1;Parallel query works by querying multiple partitions in parallel. However, data from an individual partitioned container is fetched serially with respect to the query setting the
maxDegreeOfParallelismproperty to a value of-1effectively tells the SDK to manage this setting. Setting the MaxDegreeOfParallelism to the number of partitions has the maximum chance of achieving the most performant query, provided all other system conditions remain the same. -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
Again, this should have a slight impact on your performance time.
-
Back in the code editor tab, locate the following line of code:
int maxItemCount = 100;Replace that line of code with the following code:
int maxItemCount = 500;We are increasing the amount of items returned per “page” in an attempt to improve the performance of the query.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You will notice that the query performance improved dramatically. This may be an indicator that our query was bottlenecked by the client computer.
-
Back in the code editor tab, locate the following line of code:
int maxItemCount = 500;Replace that line of code with the following code:
int maxItemCount = 1000;For large queries, it is recommended that you increase the page size up to a value of 1000.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
By increasing the page size, you have sped up the query even more.
-
Back in the code editor tab, locate the following line of code:
int maxBufferedItemCount = -1;Replace that line of code with the following code:
int maxBufferedItemCount = 50000;Parallel query is designed to pre-fetch results while the current batch of results is being processed by the client. The pre-fetching helps in overall latency improvement of a query. MaxBufferedItemCount is the parameter to limit the number of pre-fetched results. Setting MaxBufferedItemCount to the expected number of results returned (or a higher number) allows the query to receive maximum benefit from pre-fetching.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
This change should have decreased your query time by a small amount.
-
Click the 🗙 symbol to close the terminal pane.
Reading and Querying Items
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the PeopleCollection node, and then select the Items option.
-
Take note of the id property value of any document as well as that document’s partition key.
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); } -
Add the following line of code that will store a SQL query in a string variable (replacing example.document with the id value that you noted earlier):
String sql = "SELECT TOP 1 * FROM c WHERE c.id = 'example.document'";This query will find a single item matching the specified unique id.
-
Add the following line of code to create an item query instance and get the first page of results. We’ll also print out the value of the RequestCharge property for the page and then the content of the retrieved item:
CosmosQueryRequestOptions options = new CosmosQueryRequestOptions(); peopleContainer.queryItems(sql, options, Member.class) .byPage() .next() .flatMap(page -> { logger.info("\n\n" + "{} RUs for\n" + "{}" + "\n\n", page.getRequestCharge(), page.getElements().iterator().next()); return Mono.empty(); }).block(); -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see the amount of RUs used to query for the item. Make note of the LastName object property value as you will use it in the next step.
-
Click the 🗙 symbol to close the terminal pane.
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); } -
Add the following code to use the
readItemmethod of theCosmosAsyncContainerclass to retrieve an item using the unique id and the partition key set to the last name from the previous step. Add a line to print out the value of the RequestCharge property:int expectedWritesPerSec = 200; int expectedReadsPerSec = 800; double readRequestCharge = 0.0; peopleContainer.readItem("example.document", new PartitionKey("<LastName>"), Member.class) .flatMap(response -> { readRequestCharge = response.getRequestCharge(); logger.info("\n\n{} RUs\n\n",readRequestCharge); return Mono.empty(); }).block(); -
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see that it took fewer RUs to obtain the item directly if you have it’s unique id.
-
Click the 🗙 symbol to close the terminal pane.
Setting Throughput for Expected Workloads
Using appropriate RU settings for container or database throughput can allow you to meet desired performance at minimal cost. Deciding on a good baseline and varying settings based on expected usage patterns are both strategies that can help.
Estimating Throughput Needs
-
We’ll start out by looking at actual usage of your Cosmos account for these labs. Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Metrics link on the left side of the blade under the Monitoring section. Observe the values in the Number of requests graph to see the volume of requests your lab work has been making to your Cosmos containers.
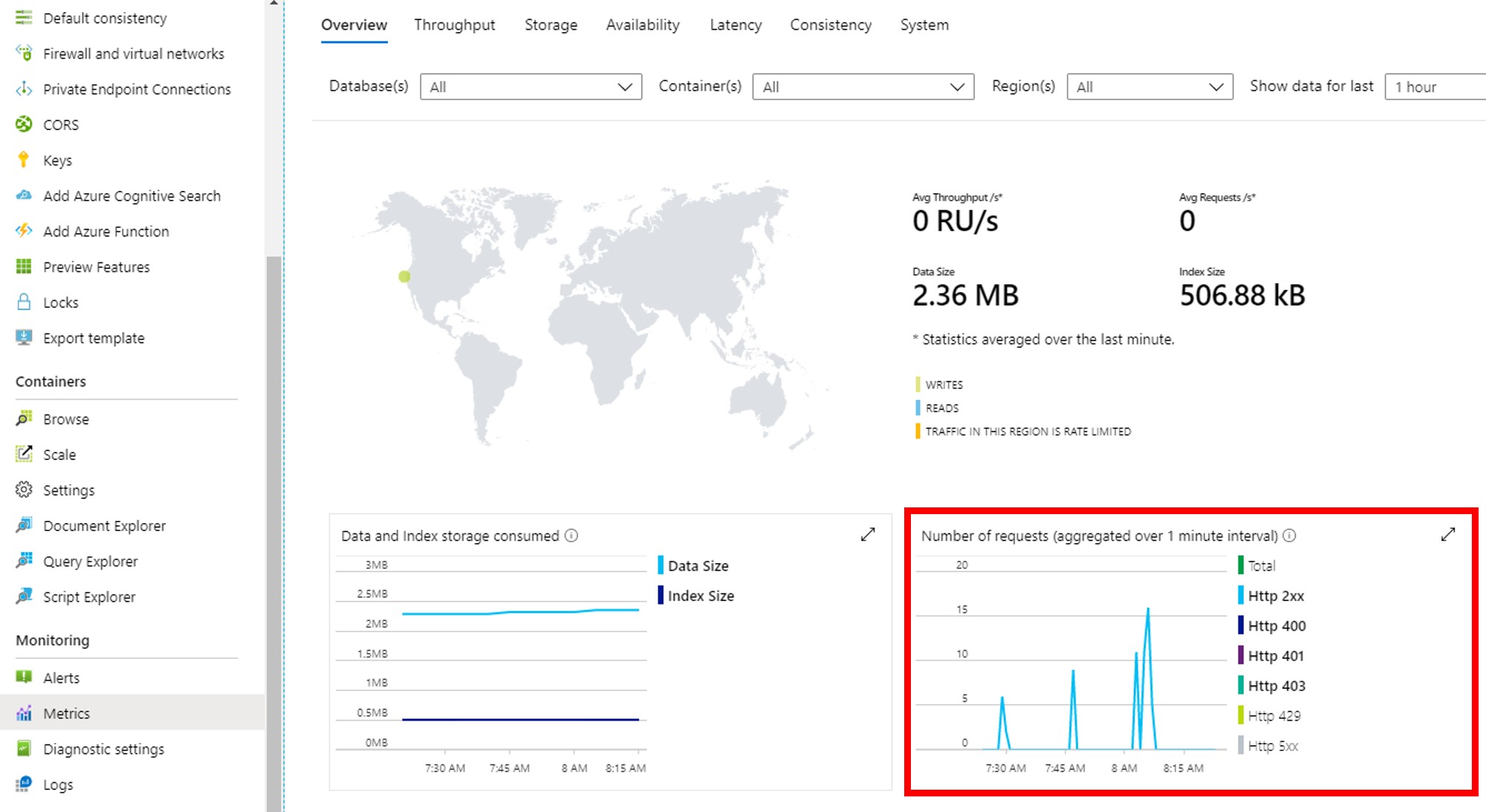
Various parameters can be changed to adjust the data shown in the graphs and there is also an option to export data to csv for further analysis. For an existing application this can be helpful in determining your query volume.
-
Return to the Visual Studio Code window and locate the WriteLineAsync line within the
mainmethod in Lab09Main.java:logger.info("\n\n{} RUs\n\n",response.getRequestCharge()); -
Following that line, add the following code to use the
createItemmethod of theCosmosAsyncContainerclass to add a new item and print out the value of the RequestCharge property:double writeRequestCharge = 0.0; Member member = new Member(); CosmosItemResponse<Member> createResponse = peopleContainer.createItem(member).block(); writeRequestCharge = createResponse.getRequestCharge(); logger.info("{} RUs", writeRequestCharge); -
Now, find the following line after the
createItemReactive Streamlogger.info("\n\n{} RUs\n\n",response.getRequestCharge());Below this line add the following line of code to print out the estimated throughput needs of our application based on our test queries:
logger.info("\n\nEstimated load: {} RU per sec\n\n", readRequestCharge * expectedReadsPerSec + writeRequestCharge * expectedWritesPerSec);These types of numbers could come from planning a new application or tracking actual usage of an existing one. Details of determining workload are outside the scope of this lab.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see the total throughput needed for our application based on our estimates, which can then be used to guide our provisioned throughput setting.
-
Click the 🗙 symbol to close the terminal pane.
Adjusting for Usage Patterns
Many applications have workloads that vary over time in a predictable way. For example, business applications that have a heavy workload during a 9-5 business day but minimal usage outside of those hours. Cosmos throughput settings can also be varied to match this type of usage pattern.
-
Delete the code you added in
mainso thatmainonce again looks like this:public static void main(String[] args) { CosmosAsyncClient client = new CosmosClientBuilder() .endpoint(endpointUri) .key(primaryKey) .consistencyLevel(ConsistencyLevel.EVENTUAL) .contentResponseOnWriteEnabled(true) .buildAsyncClient(); database = client.getDatabase("FinancialDatabase"); peopleContainer = database.getContainer("PeopleCollection"); transactionContainer = database.getContainer("TransactionCollection"); client.close(); } -
Add the following code to retrieve the current RU/sec setting for the container:
int throughput = peopleContainer.readThroughput().block().getProperties().getManualThroughput();Note that the type of the Throughput property is a nullable value. Provisioned throughput can be set either at the container or database level. If set at the database level, this property read from the Container will return null. When set at the container level, the same method on Database will return null.
-
Add the following line of code to print out the provisioned throughput value:
logger.info("{} RU per sec", throughput); -
Add the following code to update the RU/sec setting for the container:
peopleContainer.replaceThroughput(ThroughputProperties.createManualThroughput(1000)).block();Although the overall minimum throughput that can be set is 400 RU/s, specific containers or databases may have higher limits depending on size of stored data, previous maximum throughput settings, or number of containers in a database. Trying to set a value below the available minimum will cause an exception here.
-
Save all of your open editor tabs.
-
Run the project.
-
Observe the output of the console application.
You should see the initial provisioned value before changing to 1000.
-
Click the 🗙 symbol to close the terminal pane.
-
Return to the Azure Portal (http://portal.azure.com).
-
On the left side of the portal, click the Resource groups link.
-
In the Resource groups blade, locate and select the cosmoslab Resource Group.
-
In the cosmoslab blade, select the Azure Cosmos DB account you recently created.
-
In the Azure Cosmos DB blade, locate and click the Data Explorer link on the left side of the blade.
-
In the Data Explorer section, expand the FinancialDatabase database node, expand the PeopleCollection node, and then select the Scale & Settings option.
-
In the Settings section, locate the Throughput field and note that is is now set to 1000.